
ブロックとスレッドの関係
GPUの関数(カーネル)を呼び出すときは、以下のようにして呼び出します。

以下に例として、testカーネルを動かしているプログラムを記載します。
#include <stdio.h>
__global__
void test()
{
int idx = blockIdx.x * blockDim.x + threadIdx.x;
printf("idx : %d \n", idx);
}
int main(void)
{
test << <1, 10 >> > ();//カーネルの呼び出し
cudaDeviceSynchronize();
}下に簡単に意味を説明します。
- __global__ :CPUから呼び出されるGPUの関数識別子
- blockIdx.x :ブロックのナンバー
- blockDim.x :ブロックの大きさ
- threadIdx.x :スレッド番号
上記のプログラムの出力結果を以下に記載します。
idx : 0
idx : 1
idx : 2
idx : 3
idx : 4
idx : 5
idx : 6
idx : 7
idx : 8
idx : 9このプログラムでは下のようにサイズが10のブロックを1つ作っています。
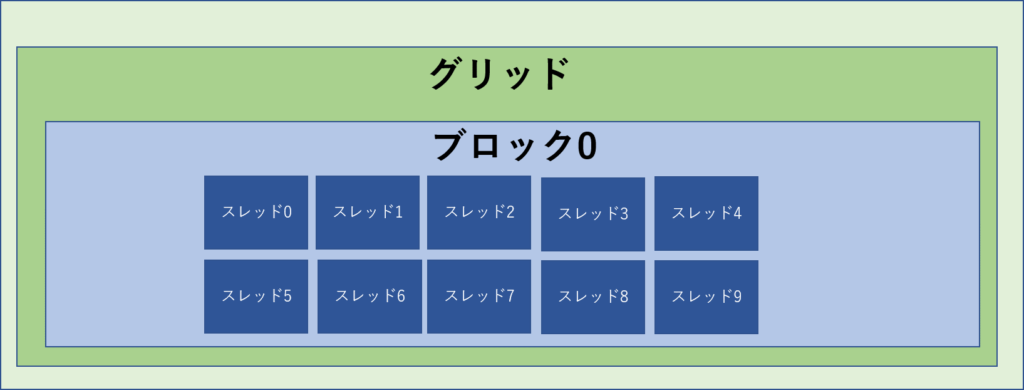
ブロックの中にはスレッドが作成されます。このスレッド1つ1つがプログラムを実行しています。
次にブロックの数を1つ増やして実行してみます。
#include <stdio.h>
__global__
void test()
{
int idx = blockIdx.x * blockDim.x + threadIdx.x;
printf("idx : %d \n", idx);
}
int main(void)
{
test << <1, 11 >> > ();
cudaDeviceSynchronize();
}実行結果です。
idx : 0
idx : 1
idx : 2
idx : 3
idx : 4
idx : 5
idx : 6
idx : 7
idx : 8
idx : 9
idx : 10idxが10まで増えたことが分かります。
この時のブロックのイメージは下のようになります。
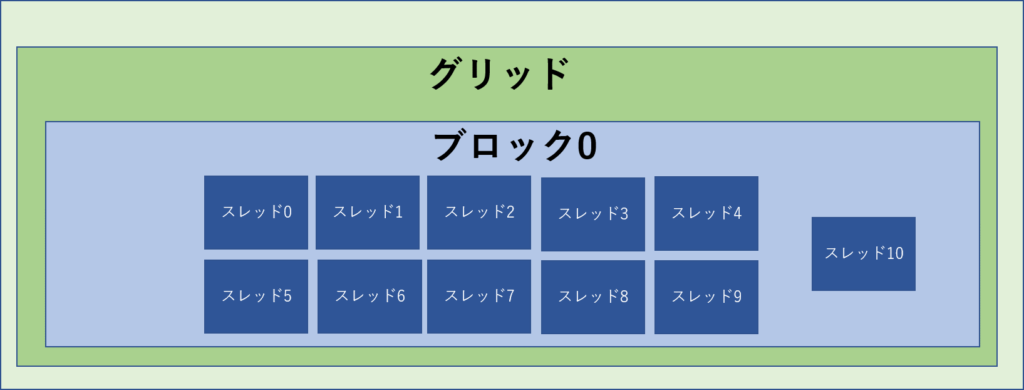
次に、ブロックサイズを1つ増やした場合です。
#include <stdio.h>
__global__
void test()
{
int idx = blockIdx.x * blockDim.x + threadIdx.x;
printf("idx : %d \n", idx);
}
int main(void)
{
test << <2, 10 >> > ();
cudaDeviceSynchronize();
}出力結果はこうなります。
idx : 0
idx : 1
idx : 2
idx : 3
idx : 4
idx : 5
idx : 6
idx : 7
idx : 8
idx : 9
idx : 10
idx : 11
idx : 12
idx : 13
idx : 14
idx : 15
idx : 16
idx : 17
idx : 18
idx : 19idxが19まで増えたことが分かります。
ブロックのイメージは以下になります。
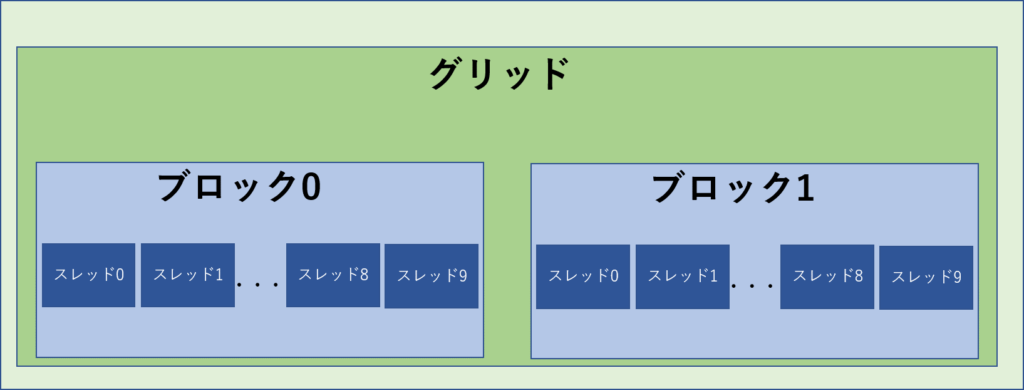
blockIdx.x とblockDim.xの説明
blockIdx.xとblockDim.xについて説明します。
先ほどのグリッドサイズ2、ブロックサイズ10の時のblockIdx.xとblockDim.xは以下のようになります。
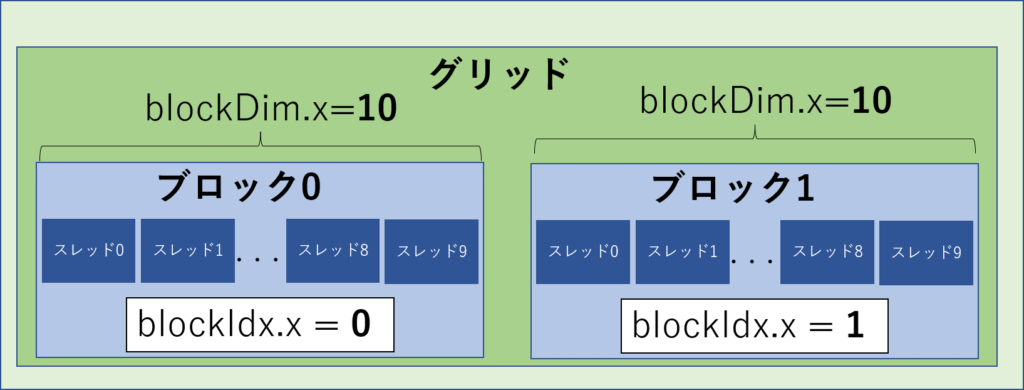
ワープ
ブロック内のスレッドは32スレッド単位で動きます。この32スレッド単位をワープといいます
この1つのワープ内のスレッドは同時に動きますが、別のスレッドのワープは別々に動きます。
例として、ブロックサイズ33(ワープ数2つ)を動かしてみます。
#include <stdio.h>
__global__
void test()
{
int idx = blockIdx.x * blockDim.x + threadIdx.x;
printf("idx : %d \n", idx);
}
int main(void)
{
test << <1, 33 >> > ();
cudaDeviceSynchronize();
出力結果
idx : 32
idx : 0
idx : 1
idx : 2
idx : 3
idx : 4
idx : 5
idx : 6
idx : 7
idx : 8
idx : 9
idx : 10
idx : 11
idx : 12
idx : 13
idx : 14
idx : 15
idx : 16
idx : 17
idx : 18
idx : 19
idx : 20
idx : 21
idx : 22
idx : 23
idx : 24
idx : 25
idx : 26
idx : 27
idx : 28
idx : 29
idx : 30
idx : 31idx : 32が一番最初にきていることが分かります。これは2つめのワープが1つめのワープより先に動いたことになります。
シェアードメモリ
スレッド同士はデータの受け渡しはできません。
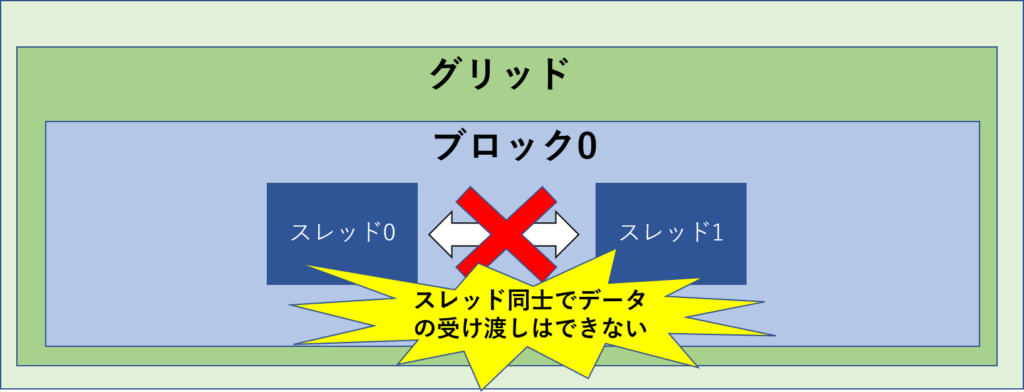
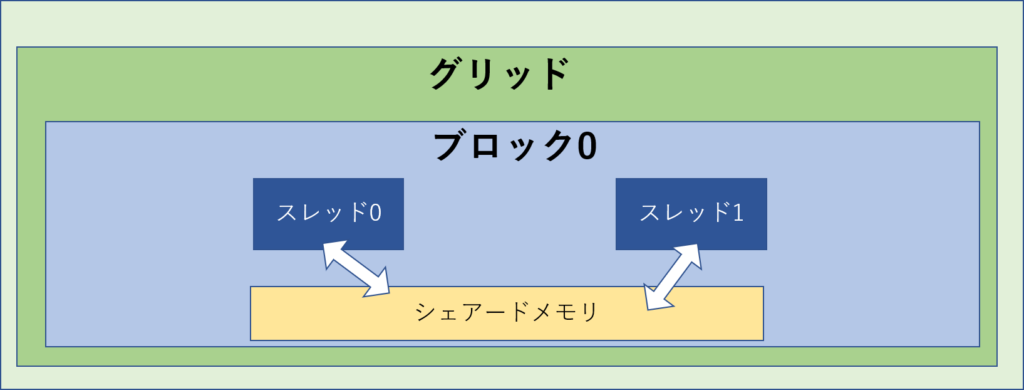
しかし、同じブロック内であれば、シェアードメモリを使うことで、データの受け渡しはが出来ます。
シェアードメモリのサイズを動的に決定するときは、以下のようにカーネルを呼び出します。
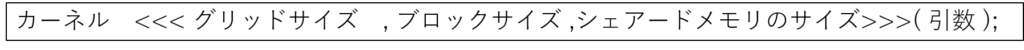
シェアードメモリの宣言は以下のようにやります。
__global__
void test()
{
extern __shared__ float sdata[]; //シェアードメモリの宣言
int idx = blockIdx.x * blockDim.x + threadIdx.x;
printf("idx : %d \n", idx);
}
int main(void)
{
test < <<1, 10 , sizeof(float)* 10 >> > ();
cudaDeviceSynchronize();
}上記で要素数10のシェアードメモリを宣言したことになります。
シェアードメモリを使用した配列の総和を求めるプログラムを例として作成したので、こちらをご覧ください。



コメント